
Building Private Cloud:
Storage Solution
In this post we're going to switch gear and talk about storage solutions, which is also an important part of any cloud deployment. We'll cover some general choices for private cloud, talk about hardware limitations in my setup, and go over a few storage solutions I attempted and either failed or succeeded.
General Discussions
There're a few aspect we need to consider when choosing storage solutions for a cluster. Some of them are more important and other are less based on your actual use case. The ones in Italic is what (I think) is more important for my setup.
- Performance: if the solution provide good (or at least enough) and consistent performance to file access, measured by sequential/random read/write latency/throughput. We'll cover an example of performance benchmarking later in this post. Some major aspects to consider: hardware/network performance, data locality, access pattern, etc.
- Reliability: the ability to withstand failure and recover. This requires the system to contain certain amount redundancy in terms of service provider, and backup mechanism to prevent data loss.
- Security: probably one of the most important but under-rated aspect, but usually considered under the larger picture of the security of the whole cluster.
- Scalability: if the solution is easy to scale with the growth of the cluster without serious disruption of service or changing architecture entirely. This might be less of a concern in the context of a home cluster, because it usually doesn't scale that much or that fast.
- Cost-effectiveness: if the cost of building such solution is good (low) considering all the properties mentioned above. Unlike for commercial data centers, there usually isn't a good quantitative way of measuring this for home clusters. It's more about a combination of the actual bucks you put in for the hardware (or software), plus the time spent in implementing and maintaining it.
Now let's talk about some major solutions that we can potentially use:
- NAS (Network Attached Storage): provides file-level storage accessed over a network. It is very commonly used for shared storage in compute clusters where multiple nodes need access to the same files. It is usually implemented with NFS or SMB protocol, and the underlying storage could vary from a consumer level NAS product with all the RAID and security already configured, or one node on the cluster with a large disk/SSD.
- Distributed File System: distribute data across multiple storage nodes, providing scalability and fault tolerance. Examples include HDFS (Hadoop File System), GlusterFS and CephFS. This gives us a unified solution with the flexibility to configure redundancy, fault-tolerance and security based on our use case.
- Cloud Storage Services: such as AWS EBS, AWS S3, Google Cloud Storage, etc. Considering the network IO performance and cost for hosting data and network IO (which is kind of against my purpose of building private cluster), these options are mostly used for cold storage or backup.
Hardware Limitations
As mentioned in my previous post, my cluster is setup on the Turing Pi 2 computing board, which has inherent hardware and connectivity limitations that's covered in Specs and IO ports doc:
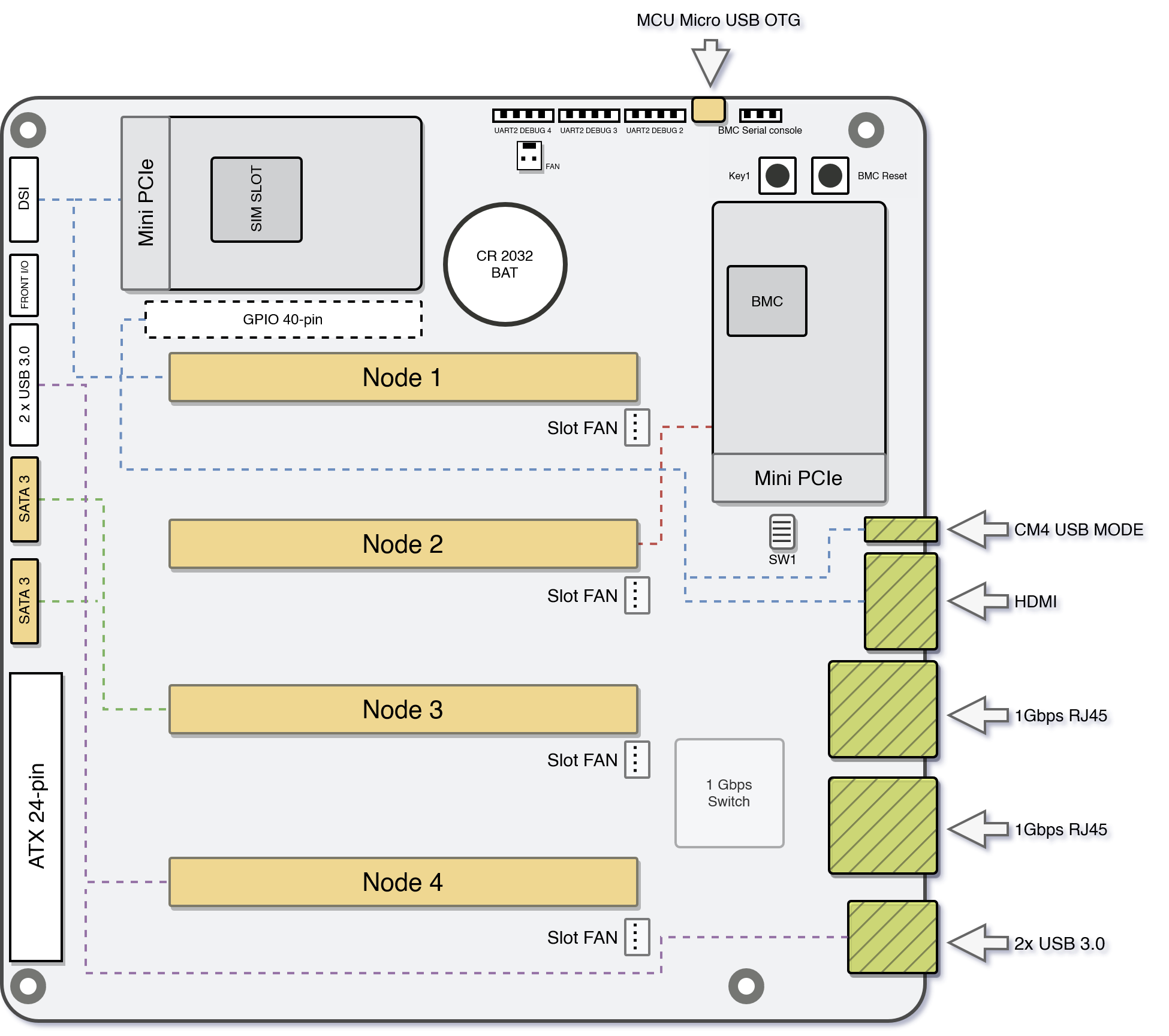
Turing Pi 2 Front Side IO Specification
- Only node 1 and 2 have mini-PCIe connectivity, so it's hard to implement any distributed solution with consistent storage on each node.
- With Raspberry Pi CM4, the PCIe compatibility is not trivial and very uncertain. Jeff Geerling built a RPi PCIe Database which contains some tested SSD cards that's supposed to work with CM4. But the data might be stale, and sourcing (old) hardware of specific model could be hard and expensive. Will cover more on this later.
- The M.2 slots for NVME drives on the back for each node seems very promising, but they only work with compute modules other than RPi CM4 *. I only have one RK1 on node 4 (actually that's the reason I bought the RK1 in the first place)
- 2x SATA3 connectivity for node 3, which should be able to work with most SATA based drives. But that requires additional space in the casing for mounting the hardware so I haven't tested that yet.
In conclusion, as a light-weight embedded approach to self-hosting, the Turing Pi 2 board is not designed to have any sort of unified large-capacity IO across all nodes. As a result we'll have to give up redundancy of some sort, and implement something of easy but robust and fits better for our context.
Solutions
In this section we'll talk about some simple solutions I tried in the context of my use case: hosting various services on a k8s cluster. For solutions that worked, I'll share the implementation and simple performance benchmarking, and for others we can discover how they might failed in later sections.
- SD cards or onboard eMMC: For all compute modules that work on Turing Pi 2, they either have mini-SD card slot (e.g. on the adapter for CM4), or on board eMMC (e.g. RK1). As they are so close to the compute ("data locality"), they deliver good enough performance overall. But there're multiple drawbacks:
- They're usually small, especially eMMC. Either 32G or 64G top, or you need to pay some decent price for 512G or 1T micro-SSD card that's less performant and reliable than other solutions.
- The OS is usually installed on the SSD card or eMMC due to locality, so storing data on them doesn't provide enough isolation and security for the system. Also it will be much harder to connect and recover if your OS crashes.
- M.2 SSD through mini-PCIe: This is the solution I have struggled for the longest time. I used to have 4 RPi CM4 for the nodes and relying on this to work as my primary storage solution. But since then I have had so many weird problems with the compatibility that it's still not fully working for me. I'll probably get back to this issue and solve it, but for now here's some points to note:
- Difference between mSATA and mini-PCIe: This is a very confusing point because mSATA and mini-PCIe looks the same on the hardware side, but their underlying data transmission standard is different (SATA and PCIe). I'm able to plug in an mSATA SSD (e.g.) on the Turing Pi 2 but it only has PCIe compatibility.
- Adapter needed: Another problem is that somehow nearly all SSD cards on the market with this form factor are working with SATA standards, so we have to use an M.2 SSD and an M.2-to-mini-PCIe adapter (e.g.) to use it on this board.
- Hardware-firmware-system compatibility: I'll keep this part simple and save the details for another post, but according to this bug or this Github issue, there're known issues for NVME SSD on RPis with PCIe port. The current compatibility regarding any combination of SSD producer/model, mother board connectivity and OS running on RPi is very unclear, and could take a long time of trail-and-error for one to achieve a working solution.
- M.2 NVME on the back: After (tentatively) giving up the previous solution, I bought a RK1 which is connected with the backside M.2 port, and it worked flawlessly. I'm using a 2T ZHITAI TiPlus5000 I bought from China.
- Standalone NAS: This is also another convenient option if you already have a NAS running in your local network. The performance might not be as good as previous options (as we'll see in later benchmarking results), but you cannot beat the convenience of it.
Implementation
My current solution combines the M.2 NVMe and NAS option. While it's not that scalable, reliable or secure, it's relatively straightforward to implement and offers satisfactory performance.
To support persistent storage for k8s services, we usually mount a Volume of hostPath type, which is equivalent of mounting a directory to docker container from the host. But usually for the sake of resource utilization and load balancing, we want the pods to be able to run on any node instead of fixed to one. To achieve that we need an NFS server for the storage, and mount it to the same path on every node. We will cover some major steps to achieve this solution.
Configure New Disk
These steps are applicable when we just plugged in a new disk on to one host.
- Run
lsblkto list block storage devices, and check if the disk is present
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
mmcblk0 179:0 0 29.1G 0 disk
├─mmcblk0p1 179:1 0 512M 0 part /boot/firmware
└─mmcblk0p2 179:2 0 28.6G 0 part /
mmcblk0boot0 179:32 0 4M 1 disk
mmcblk0boot1 179:64 0 4M 1 disk
nvme0n1 259:0 0 1.9T 0 disk # <-------
- Note that there isn't any partition on the disk so it's not usable. Create partition on it with
fdiskwith default configurations. For a fresh new disk the commands should ben(for new partition),p(for primary partition),1(for just 1 partitions) andw(for write the changes to the disk)
$ sudo fdisk /dev/nvme0n1
Welcome to fdisk (util-linux 2.36.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): n
Partition type
p primary (0 primary, 0 extended, 4 free)
e extended (container for logical partitions)
Select (default p): p
Partition number (1-128, default 1): 1
First sector (2048-10485759, default 2048):
Last sector, +/-sectors or +/-size{K,M,G,T,P} (2048-10485759, default 10485759):
Created a new partition 1 of type 'Linux filesystem' and of size 5 GiB.
Command (m for help): w
The partition table has been altered.
Syncing disks.
- Make a file system on the partition, which correspond to what we used to call "format the disk"
To verify, run
lsblkagain and you should see the newly created partition under the disk.
sudo mkfs -t ext4 /dev/nvme0n1p1
- Create a mounting point for the file system and setup correct owner and permissions
To verify, run
lsblk -o NAME,FSTYPE,SIZE,MOUNTPOINTand check the FSTYPE column for FS format information
sudo mkdir /mnt/<fs_name>
sudo chown -R <user>:<user> /mnt/<fs_name>
sudo chmod 764 /mnt/<fs_name>
- For a one-time testing, using the following command to mount the disk to the mounting point
mount /dev/nvme0n1p1 /mnt/<fs_name>
- To automatically mount on system restart, check the disk partition UUID and add the a line to
/etc/fstab
To verify, run
df -hwhich will show file system usage in all available file systems, including the newly mounted disk.
$ sudo blkid
/dev/nvme0n1p1: UUID="e3aecbef-..." BLOCK_SIZE="4096" TYPE="ext4" PARTUUID="..."
...
# add the following line to /etc/fstab
UUID=e3aecbef-... /mnt/m2 ext4 defaults 1 1
Setup NFS Server
For the NAS solution, check instructions from the NAS provider (e.g. QNAP) on how to host NFS server in local network and set corresponding permissions.
To share a disk on one node with NFS server, check installing instructions for the corresponding linux distribution of the host (Ubuntu, DietPi, etc.). Generally for any Debian based system you can install with apt
sudo apt update
sudo apt install nfs-kernel-server
Shared directories and permissions can be configured in /etc/exports like this:
/mnt/<fs_name>/shared <node1_ip>(rw,sync,no_subtree_check) <node2_ip>(rw,sync,no_subtree_check) ...
Here I'm only giving access to other nodes in the cluster for better security. After this, run sudo exportfs -a to update the config to NFS server.
One thing to mention is that although NFS server can be controlled by systemctl, you will only see active (exited) in the service status. This doesn't mean that the NFS server failed to start or crashed. NFS service is in kernel space, not user space. As a result no active service is running in the user space, hence the status. The service you see with systemctl is more like a process to trigger the actual NFS server in kernel, and it successfully finished and exited.
Mount NFS on Clients
Apply the following steps on all other nodes that need to access the NFS server.
- First, create the mounting point and set correct owner and permissions:
sudo mkdir /mnt/<fs_name>/shared
sudo chown -R <user>:<user> /mnt/<fs_name>/shared
sudo chmod 764 /mnt/<fs_name>/shared
- For a one-time testing, using the following command to mount the disk to the mounting point
mount -t nfs <nfs_server_ip>:/mnt/<fs_name>/shared /mnt/<fs_name>/shared
- To automatically mount on system restart, add the a line to
/etc/fstab
Use
df -hto verify.
<nfs_server_ip>:/mnt/<fs_name>/shared /mnt/<fs_name>/shared nfs defaults,bg 0 0
One thing to notice is how file system permissions work across NFS servers and clients. Pay attention to root_squash and all_squash config options, and also matching user ids between server and client is something we can consider.
Benchmarking
I have done a set of simple filesystem IO benchmarking with my current setup using sysbench. With the fileio built-in test, we can easily test read/write latency/throughput under sequential or random access. Sysbench doesn't seem to have an official documentation, but you can check this on how to run and config the fileio benchmark.
Here's the setup of the benchmarks:
- Benchmarks to run: (sequantial, random) x (read-only, write-only) workload on 10G of data with 4 threads for 120 seconds.
- Target file system: mounted standalone NAS, and NVME hosted with NFS
- Target nodes: rk1 which is plugged with NVME and hosting NFS, rpicm4n1 which is mounting the NVME as NFS client
- Measure overall throughput and p99 latency
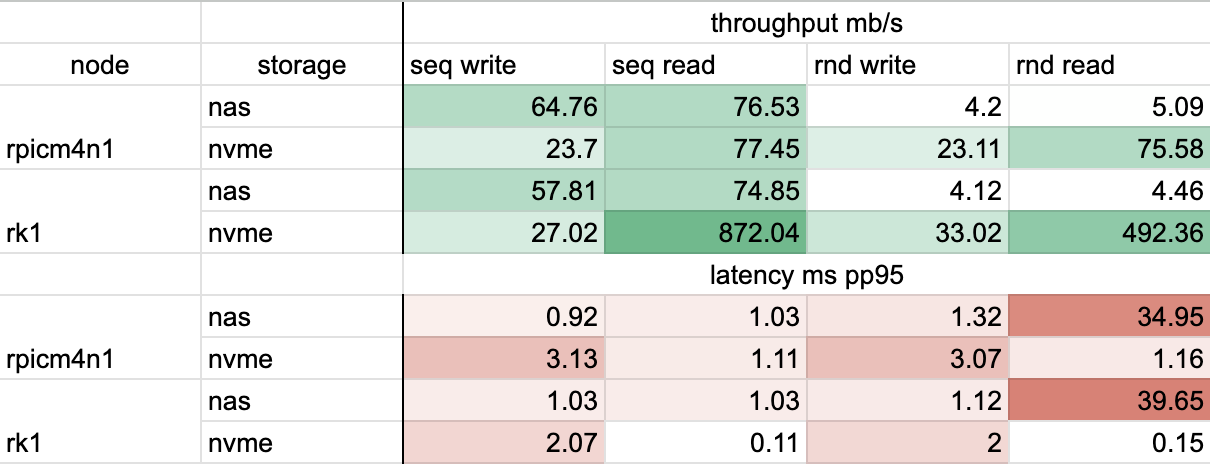
Simple Benchmark Result with sysbench fileio
The result verifies most of my assumptions, and also shows some potential improvements in the future:
- Most of the time NAS performs the same or worse than NVME, except for sequential write. I don't have a clear answer for that but maybe NAS has some sort of write cache?
- NVME performs much better at random read/write due to the obvious difference between SSD and HDD, which is the main reason for me to implement the NVME-over-NFS solution.
- Performance difference between NFS client and host is visible but not too bad (comparing nvme results between 2 tested nodes), which means the network IO is controlled well on the motherboard. Sequential/random read on client node is about the same while differs ~2x on host, which means that the bottleneck is indeed network IO.
Conclusion and Future Work
We should probably stop here as this is already a lengthy post. I know that the final solution I settled with is in no way a perfect solution, but it satisfied basic requirements while still relatively easy to implement. A few followup work to consider:
- Get to the bottom of the "PCIe SSD on RPi" rabbit hole and fully utilize the mini-PCIe connectivity for node 1 and 2.
- Investigate some distributed file system solutions (maybe CephFS?) and implement one for better reliability and performance (and fun).
- Benchmark more storage solutions, including micro-SSD and onboard eMMC, and any future solutions.
Hope you enjoyed, and happy hacking!
For the list of the series of blog posts about building private cloud, click here.
Markdown source