
System Design:
Twitter Hashtag Popularity by Time
2021-12-31 11:45:10 system System Design Big Data Interview
Yesterday I came across a quite nicely setup system design interview question while I was preparing for my upcoming interviews. So I feel like sharing it here as a good reference.
The problem
So without further ado, here is the problem itself:
Design a Twitter hashtag popularity query system that could (1) ingest twitter data and (2) give popularity histogram when queried with a specific hashtag and a time range.
Notice that the problem description is intentionally left ambiguous in multiple ways, so that the candidate (me) should start exploring different possible scenarios and discuss how they would affect the overall solution. Specifically here's some points I initially find that worth mentioning:
- How are we going to ingest Twitter data? Obviously we shouldn't have access to Twitter internal infrastructures (which would make this problem much more boring), so we have a few options:
- (My initial assumption) We don't have any special APIs to call twitter, which makes this a web crawler scenario. A more realistic solution would to have a list of hashtags we care about, and constantly crawl the timeline page of these hashtags. This is a regression in capability comparing to the original problem, since interviewer might require query on any possible hashtags.
- We have some arrangements with Twitter and have a
get_tweets_between(start_time, end_time)API, which will return all tweets tweeted between these times. There're two options regarding this API design over the tradeoff between data efficiency and latency requirement:- The simple way is to call this API as frequently as the finest granularity we need, which gives us best latency, but have larger network overhead and pressure over Twitter's API service. The following discussion about solution is going to build upon this relatively simple version of API.
- If the API could have pagination, we can call the API with longer intervals, which on the contrary is more data efficient, but our data will have longer latency and less realtime.
- What is the query used for in a business sense? More specifically what is the frequency of this query, and what is the distribution of the possible time range queried? To me this is more of a business insight scenario, where the user would be a small group of analysts so the query qps shouldn't be anything to worry about. As for time range, we could be targeting a difficult scenario where the query could ask data withing a few years, and with 5 minutes as its finest granularity at the same time.
Solution
According to Grokking system design we should follow certain steps to tackle system design questions including analyse requirement and constraints, get a component diagram of the basic system, and start to go deep into some specific bottleneck of tradeoff in the system that we need to make.
For this problem, we did the requirement and constraints part already. Just need to add another important part: always ask for the scale of the problem, maybe the amount of data or qps of requests the solution needs to deal with, and it should be as specific as a number (e.g. for this problem there's around 500 million tweets generated daily, and each of them less than 140 characters.) These specific numbers gives good direction about how the system should be designed.
Now we have the simple diagram (made with excalidraw) of the components we need in this system, and we can expand the discussion around that.
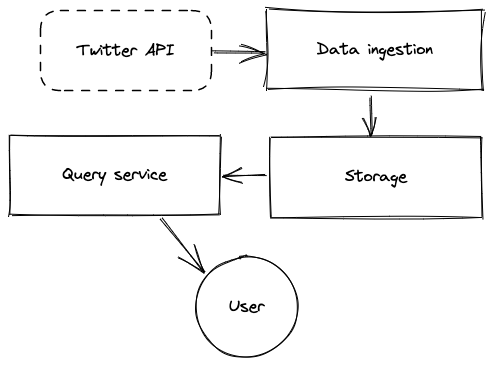
Data ingestion
There isn't much to talk about data ingestion as we already had some discussion about possible ways to use the Twitter API. Some other points that probably worth some thoughts are: What if the network fails? What if the program accidentally crashes? How to do backfill? How to guarantee no data loss or duplication? Is it exactly-once or at-least-once delivery?
Ideally you should have a checkpoint file on a persistent file system that track the latest batch of data that actually successfully stored, and an auto restarting puller program should be good enough. Of course you need good monitoring and alerting to attract human attention when there's network issue etc.
Data model
The data model for this problem is quite straight forward, as we only care about number of tweets with a specific hashtag in a specific time range. A unit of data should look like this:
hashtag time_range count
#NASA (2021-12-31 16:45, 2021-12-31 16:50) 42
Here the time range equals to the finest granularity we care about. If we can aggregate data over it before storage, we will have the best data efficiency we can get.
Database vs. File system
It is a long lasting debate about which is more suitable for data storage: database (no matter RDBMS or NoSQL) or file like storage (plain file system, HDFS or object storage like S3). Particularly for this problem, file like storage should be a better choice for the following reasons:
- Data structure: This problem deals with unstructured stream of data instead of structured data, which is much more suitable for file based storage for better data efficiency.
- Latency requirement: The use case doesn't require massive amount of low latency queries, so database with optimization over query performance is not necessary.
So the proposed data layout should be something like data written by Spark with static partitions over different granularity:
# first 5 minutes between 16:00 and 17:00 of 2021-12-31
$ head data/year=2021/month=12/date=31/hour=16/0000001
# nasa 12
# nexus 2
# spark 1
# ...
This data layout works best with map reduce compute model like Spark, which will aggregate files just within the queried time range for best compute performance. There's further optimization built on this:
- Add different data sinks for all possible queried granularity, and have separate ETLs to periodically aggregate data from raw (finest granularity) data to those sinks. This will greatly improve query time when the time range is as large as a few years and granularity is larger (it is unlikely to ask for data across years and still require 5 min accuracy)
# same as above, now in the raw subdir
$ head data/raw/year=2021/month=12/date=31/hour=16/0000001
# aggregated data for the first hour of 2021-12-31
$ head data/hourly/year=2021/month=12/date=31/0000001
# aggregated data of the first day of 2021-12
$ head data/daily/year=2021/month=12/0000001
# ...
- Since the query only cares about one specific hashtag at a time, it would be wasteful to have to read data of all hashtags within that time range, which is exactly what we're doing now. Naturally we can do grouping based on a small hashed value of the hashtag name, and add that group id as a static partition in the file path. This will significantly reduce the data size needed to read on each query, based on how many group you created.
# same as above, but now only contains data of hashtags that hash to asdf
$ head data/gid=asdf/year=2021/month=12/date=31/hour=16/0000001
Given what we have discussed, it would be appropriate to have data ingestion service store the data to a event queue (e.g. Kafka) and use a Spark structure streaming job to consume and preprocess the data before sink into the storage.
Query service
As we mentioned that the query requirement is less strict in terms of service capacity or latency, there is still some aspect we could talk about:
- Result caching: query such a large dataset is very costly, so it would be nice to have a cache that can store recent query result in memory, and be able to do simple aggregation or increment updates for use cases like dashboards.
- ...What was the other aspect I was thinking about?
Afterword
Thanks my friend dkdpy for providing this interview question and had an in-depth discussion with me for ~45 min. This (should be) very helpful for my upcoming system design interviews in January. Wish me luck!
Markdown source