
RSS: Fight Against the Algorithm
2025-02-08 00:25:40 tech RSS Web Crawling Tor

xkcd.com/386 Duty Calls
Inspired by the blog I Ditched the Algorithm for RSS—and You Should Too I randomly read from HN, I self-hosted my own RSS generator + web-based RSS reader, and here's how I did it.
Motivation
I actually consider myself quite resistive to addiction, but still I find myself doomscrolling for an hour or two from time to time. The modern Internet has evolved to a state where most valuable contents are created within closed platforms, who have little to no interest in your wellbeing and need, but have great incentive to get you addicted ("Engagement") with recommendation algorithms. Billions of dolors and greatest intelligence of our generation are devoted in making the algorithms effective.
xkcd.com/802 Online Communities 2, maybe a bit outdated
While it's possible and frankly quite admirable to just give up all social media and other sources of attraction and live in a wood cabin beside Walden Pond, I'm nowhere near that level of determination, and still find some sorts of content worth consuming. So how do we take the control back from the corporations and the algorithm?
RSS to the Rescue
RSS and basically any kind of web feed works in similar ways: Instead of manually checking content update, an automatic procedure ("Feed Generator") checks periodically, keep track of the updated content metadata, and the client ("Feed Reader") can poll for updates (in the form of the cutting-edge XML™ documents) anytime it wants.
As a 25-year-old technology, RSS had its popular time, before the Internet became as closed as today. Many major content platforms used to support RSS subscription (basically hosting feed generator for themselves), and there was public feed generator with close to real-time feed pushing, thanks to economies of scale. Those days are long gone.
FreshRSS
For casual usage with already available RSS feed, all you need is a feed reader. There're many apps and platforms available1 with convenient integration to many major social media.
While I'm looking for something away from a public service provider, I settled with FreshRSS, an opensource self-hosting RSS reader with refreshing UI an simple yet complete features. The simplest deployment is just one executable and uses a local sqlite file for data storage and persistence, which is very convenient.
FreshRSS is very nice to have an official Docker image (luckily with ARM build as well), so it's fairly easy to construct a k8s Deployment and Service config to deploy it.
FreshRSS deployment and service k8s config
kind: Deployment
apiVersion: apps/v1
metadata:
name: freshrss
labels:
app: freshrss
spec:
replicas: 1
selector:
matchLabels:
app: freshrss
template:
metadata:
labels:
app: freshrss
spec:
containers:
- name: freshrss
image: freshrss/freshrss
env:
- name: TZ
value: America/Los_Angeles
- name: CRON_MIN
value: 1,31
ports:
- name: freshrss
containerPort: 80
volumeMounts:
- name: freshrss-data
mountPath: /var/www/FreshRSS/data
volumes:
- name: freshrss-data
hostPath:
path: /persistent/storage/path/freshrss/data
type: Directory
---
apiVersion: v1
kind: Service
metadata:
name: freshrss
spec:
ports:
- name: freshrss
port: 80
targetPort: freshrss
selector:
app: freshrss
As usual, I'm using hostPath volume for data persistence2, and the only 2 config needed are timezone and cron period (fetch frequency), both set by env variable. If everything goes fine, you should be able to access the service on localhost:8080 with proper port mapping:
kubectl port-forward svc/freshrss 8080:80
For now I'm exposing the service publicly through tunnelling, which allows me to access it from anywhere (to avoid the algorithms). This means I'm only depending on the user system security of FreshRSS so it's a bit risky.
Now it is already fully usable. With RSS links from public feed generator or platform natively supporting RSS, you can easily start subscribing RSS feeds. Some examples that I subscribed:
- Youtube channels can be directly added as RSS using the original channel link, e.g. https://www.youtube.com/@3blue1brown, https://www.youtube.com/@veritasium
- Hacker News RSS is a public RSS generator on HN contents. It is very capable with different features like search, replies and comments support through URL arguments. I'm just using the
pointsparameter to filter out posts that made to front page with more points than e.g. 80: https://hnrss.org/frontpage?points=80
RSS Generator
Unfortunately due to reasons we mentioned above, many (actually more and more) content platforms3 are not willing to get you access content through means other than their own website or app. They tend to have very poor RSS support, if not nothing at all. In this case we need to have our own RSS feed generator and fetch contents by ourselves.
One of the most famous opensource solution is RSSHub, a NodeJS based RSS feed generator with community driven support for many content platforms. It has an official public deployment to be directly used as feed generator4, and you can self-host as well. The problem is that
- many routs I need seems to be broken (e.g. Bilibili user dynamics example) from the official deployment
- I'm not a big fun of JS and Node ecosystem.
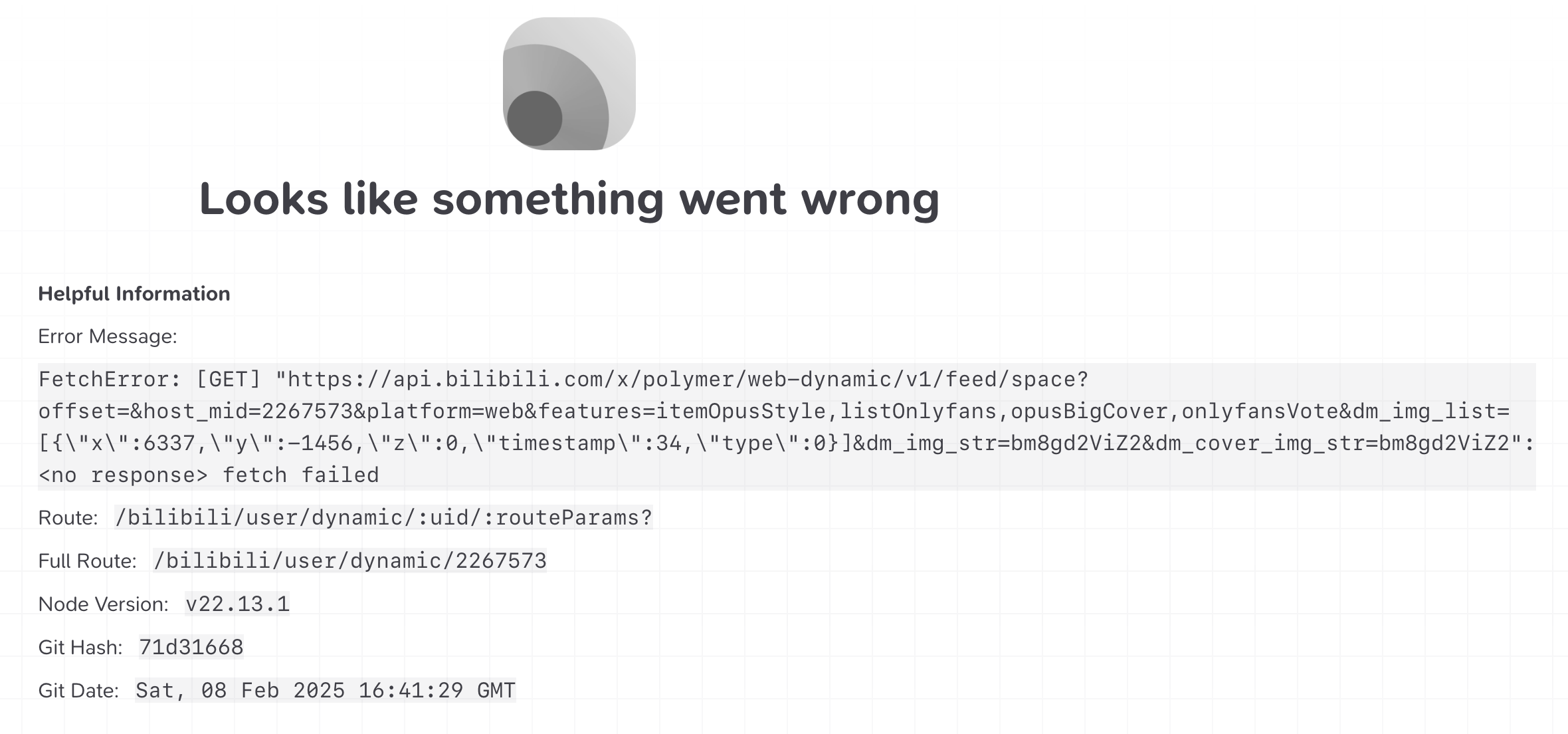
Failed fetch on RSSHub official deployment
Instead, I'm writing a simple Python RSS generator implementation using the following dependencies:
- Beautiful Soup for parsing and extracting information from HTML results.
- feedgenerator for generating RSS feed XML result.
- Flask, requests, etc. for regular server hosting and web request needs.
The generic part for generating feed is fairly easy to understand, while the real complexity lies in the ad-hoc processing logic of the content being fetched from each source, and the problems encountered trying to fetch them.
Form of Content
Some platform has functional APIs available (API docs not so much available) for you to fetch content from, while other website you have to try to fetch raw HTML page. You may find source of content for each platform from RSSHub routes source code, which could be a good reference.
Web Crawling Issues
- How do you build easily extensible infra for parsing HTML with beautiful soup?
- Simple anti-bots filtering: Correct
User-Agentin request header is needed, ans sometimes it's necessary to involve some automatic browser library (e.g. Puppeteer or Selenium WebDriver) to get over some JS trick. - Login requirement: It's usually solvable with certain cookies you get from a browser with logged in account.
requestssupport setting cookie values in request. - IP-based blocking: This can happen if you're requesting too frequently, and can be a headache especially during developing phase. The usual solution involves proxying your requests through an IP pool (torproxy maybe an option).
Fin
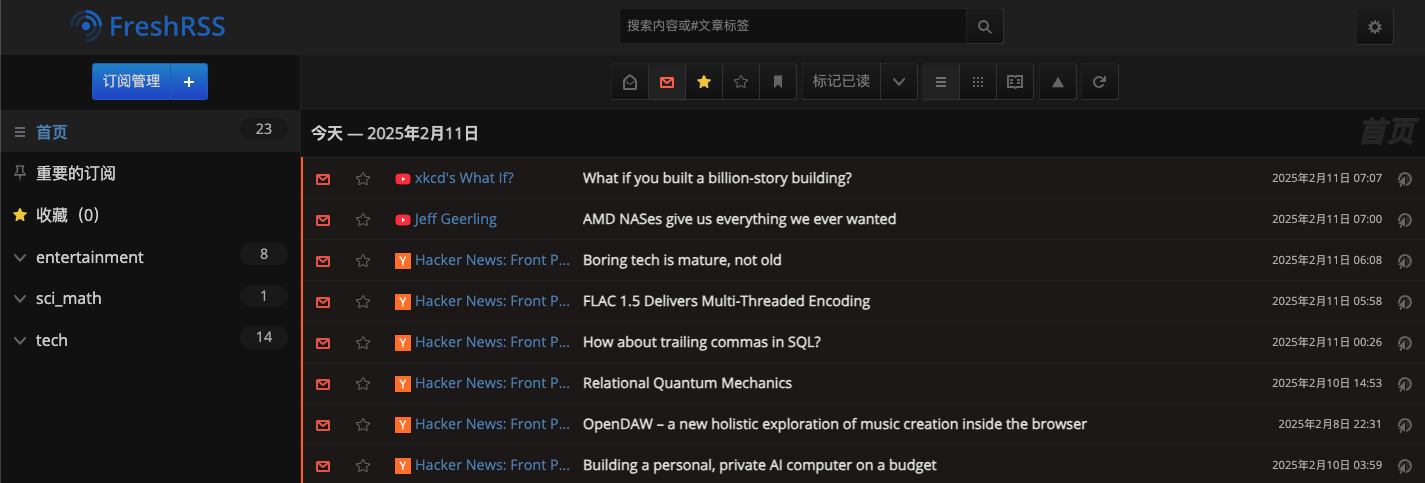
Result of my feed reader just now
Note that web crawling and proxy tooling might be used for illegal purposes. The nature of the content, the request frequency or even jurisdiction affects the legal definition and practice on this matter. This blog is not legal advice, and any technology mentioned should be used responsibly and at your own risk.